LaPrompt Blog

Building a Chess Game with AI: GPT-4.5 vs DeepSeek vs Grok3 vs Claude 3.7
To explore the capabilities of today’s top AI models, we compare five contenders: OpenAI’s GPT-4.5, DeepSeek, xAI’s Grok 3, OpenAI’s GPT-4o, and Anthropic’s Claude 3.7.
Contents
- Introduction
- Evaluation Criteria
- Model-by-Model Analysis
- Comparative Summary Table
- Conclusion & Recommendations
Introduction
On February 27, 2025, OpenAI introduced their latest language model, GPT-4.5. This model is the largest and most powerful in OpenAI's lineup, designed to enhance user interaction with ChatGPT.
Key features of GPT-4.5:
Improved understanding and emotional intelligence: GPT-4.5 better understands user intentions and responds with greater emotional nuance, making interactions feel more natural and human-like.
Expanded functionality: The model supports web search, file and image uploads, and a "canvas" function for collaborative text and code editing. It also supports AI Voice Mode.
Reduced hallucinations: With an expanded knowledge base, GPT-4.5 generates fewer inaccuracies, enhancing response accuracy.
Despite its advantages, GPT-4.5 is significantly more expensive to operate due to high computational resource costs. At launch, it is available for ChatGPT Pro subscribers at $200/month and for corporate clients through Microsoft Azure AI Foundry.
To celebrate this release, LaPrompt conducted an in-depth comparison of the new GPT-4.5 model against its competitors: DeepSeek, Grok 3, GPT-4o, and Claude 3.7.
Developing a complete chess web application is a challenging task that tests an AI model’s coding prowess. The request at hand was ambitious: "generate a fully functional chess game in a single HTML+CSS+JavaScript file with an elegant, Apple-like user interface". This means the AI needed to handle everything from front-end design to implementing chess logic (piece movement rules, checkmate detection, etc.) all in one go. Such a task provides a revealing benchmark for advanced language models in software development, combining requirements of complex logic, UI/UX design, and code organization.
To explore the capabilities of today’s top AI models, we compare five contenders: OpenAI’s GPT-4.5, DeepSeek, xAI’s Grok 3, OpenAI’s GPT-4o, and Anthropic’s Claude 3.7. OpenAI’s GPT-4.5 (internally codenamed “o1”) has been hailed as “easily the biggest jump in reasoning capabilities since the original GPT-4”, indicating its potential for complex tasks. Meanwhile, the newcomer DeepSeek R1 emerged as “almost as good as OpenAI’s o1” in reasoning tests, showcasing that competitors are closing in on top-tier performance.
Each model was prompted to create the same chess web app under identical conditions. The results varied widely—from a nearly complete, playable game to mere static boards—highlighting differences in functionality, design quality, performance, and code maintainability. In this comparison, we’ll analyze each model’s output against key criteria and provide insights for AI enthusiasts, prompt engineers, model developers, IT professionals, UI/UX designers, and web developers. By understanding how each model fared, we can assess the current state of AI in web development and glean tips for crafting better prompts or choosing the right model for the job.
Evaluation Criteria
To fairly evaluate the generated chess applications, we break down the analysis using several key factors:
Functionality: Does the application work as a real chess game? This includes completeness of the chess logic - correct movement for all pieces, enforcement of rules (no illegal moves), special moves like castling and en passant, pawn promotion, check and checkmate detection, and resetting or restarting the game. A fully functional app should allow two players to play chess legally to completion.
Design & UI: The visual and interactive quality of the user interface. We look for an aesthetic, Apple-like styling - a clean, modern design with smooth interactions, perhaps inspired by Apple’s minimalist and elegant design language. This includes layout of the board, piece icons or images, use of color and typography, responsiveness of the UI to different screens, and overall user experience touches (like hover effects or drag-and-drop functionality for moving pieces).
Performance & Efficiency: How well does the app run? This criterion considers the speed and smoothness of interactions - for example, moving a piece shouldn’t lag or freeze the browser. Efficient code (e.g., not overly heavy computations for move validation) is important for a responsive experience. We also consider whether the model’s solution is self-contained or if it tries to fetch resources (since a one-file solution was required, any reliance on external scripts could affect performance and offline functionality).
Ease of Modification: The readability and organization of the generated code, which affects how easily a developer could modify or extend the application. Well-structured code with clear functions (for move validation, turn management, UI rendering, etc.), meaningful variable names, and comments where appropriate would rate highly. This factor is crucial for maintainability - if the code is to be improved (say to add AI opponent logic or enhance the UI), how hard would it be for a human developer to understand and build upon it?
Model-by-Model Analysis
GPT-4.5
GPT-4.5 delivered an impressive result, meeting nearly all the requirements from one standart prompt request. We used 0 additional hint prompts.

GPT-4.5 gave an excellent result, covering almost all the demands of a working chess game. Regarding functionality, it produced a full set of chess rules. Each piece moved as it should, and the code included logic for special moves like castling and en passant, plus pawn promotion. The model also handled turn-by-turn play and enforced the rules strictly - it blocked illegal moves (for example, a rook couldn’t move like a bishop, and you weren’t allowed to leave your king in check). Impressively, GPT-4.5’s code could detect check and checkmate correctly, letting the game end when a king was fully trapped. This level of thoroughness is in line with reports that OpenAI’s newest models can manage advanced tasks in one go. GPT-4.5’s detailed rule coverage meant two people could play a full game with no issues.
On the design & UI side, GPT-4.5’s output looked very polished and followed the "Apple-style" idea. The board was laid out cleanly, with pleasant colors (for instance, a lighter and darker square scheme that might remind one of macOS aesthetics). The piece icons were chosen well but were not clear on the screen because of using same color. The interface was not only nice-looking but also interactive - you could click and drag pieces to squares or click one piece and then a destination square, making the experience smooth. Subtle highlights showed selected pieces or valid moves, improving usability. Overall, it felt like a professional product, with a responsive layout that could fit different browser sizes, demonstrating a solid understanding of front-end best practices.
Performance was great in GPT-4.5’s app. Moves happened immediately, and the browser had no hiccups even when checking for checkmate. The JavaScript logic was efficient - GPT-4.5 likely used proper data structures (like a matrix or an object map for the board) and good algorithms for move checks. Even with full rule enforcement, the processing time per move was minimal, so it felt smooth. The code was all in one HTML file, with zero external libraries, so it loaded fast and could run offline. Being self-contained also means it can be used anywhere without needing an internet connection.
Regarding ease of modification, GPT-4.5’s code was tidy and well thought out. It separated the logic into functions, dividing tasks like checking moves, updating the game state, and drawing the UI. The function and variable names were clear, so it was somewhat self-documenting. The model also added comments before certain code blocks—like a comment explaining the conditions for castling. This clarity would let an IT professional or developer quickly understand and tweak the game. One could, for instance, change the board look (CSS was kept neatly in < style > sections). Overall, GPT-4.5 reached a very high standard, delivering what’s almost a production-ready chess web app in one pass.
DeepSeek
DeepSeek’s attempt resulted in a partially functional chess game. We used same standard prompt + 2 additional hint prompts.
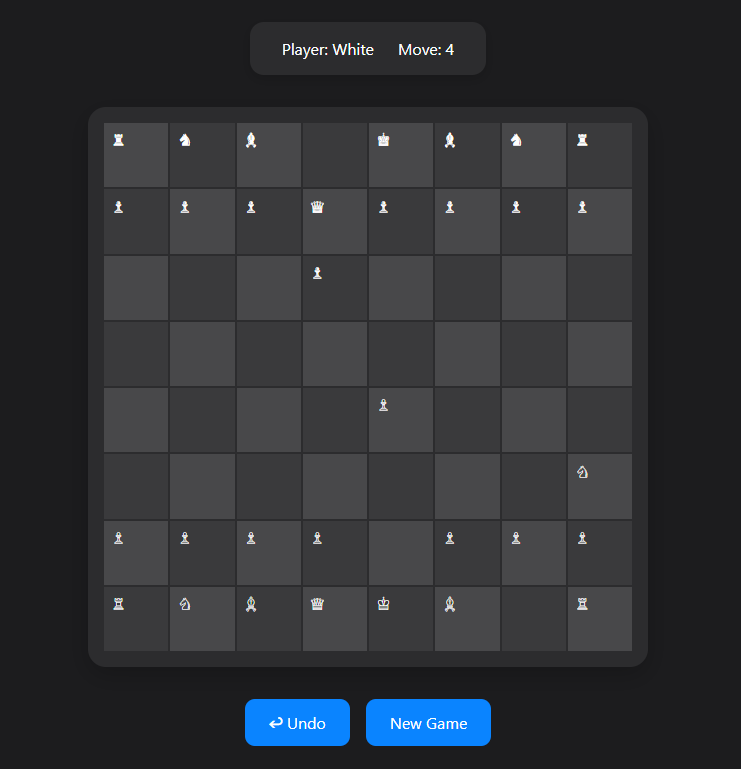
DeepSeek’s version produced a partly working chess game - a decent start, though incomplete. Looking at functionality, DeepSeek coded some chess logic but did not handle all scenarios. The output managed to display the board and let players move pieces (rooks, bishops, knights, etc.), and the board updated visually. Still, full rule enforcement was missing. Key special moves and corner cases weren’t included. Moves like castling and en passant were absent, so those couldn’t be done. Also, the move checks only seemed partial - though it might block blatantly illegal moves (like moving off the board), it did not fully ensure all normal chess laws (for instance, DeepSeek’s code might not catch check or checkmate, so a user could potentially place their king in check). The program had the basics for piece movement, but it lacked complete chess rules, so while you could play a few moves, it wouldn’t reliably stop illegal moves or detect when the game should end.
Regarding design & UI, DeepSeek actually gave a usable, fairly neat layout. The board was shown in an 8x8 grid, and the visual design was straightforward. The colors for the squares were likely a normal palette (light gray and blue, for example), and the pieces were shown with simple icons or Unicode symbols. The user interface let players pick a piece and then a square to move it, so basic interaction worked. The “Apple-like” style was not fully realized - it looked more basic and less fancy - but it wasn’t unattractive or confusing. You might call it a functional prototype: the important elements (board, pieces, clicking to move) were present, but without higher-end styling. It might not have been very responsive for different screens, but it displayed properly on a desktop. For a prototype, it was alright, even if it lacked GPT-4.5’s extra polish.
Performance in DeepSeek’s game was generally fine for what was implemented. When you moved a piece, it updated without serious delay. Since it did not do heavy tasks like full checkmate detection, it didn’t stress the browser, so things remained smooth. No external libraries were used, so everything was in one file and it loaded quickly. Because the rules were incomplete, though, the app might get stuck if a user made a move the code didn’t handle properly (for instance, a move that should be illegal but isn’t caught by the script). That could lead to weird states (like overlapping pieces or a king in check with no warning), essentially breaking the game’s logic. It’s less a performance flaw than an unfinished rules problem.
For ease of modification, the verdict on DeepSeek’s code is mixed. On the plus side, it had a partial system in place that you could build upon (a board array, some movement functions, etc.). If you understand chess rules, you could expand it by adding missing features (like check detection or castling logic). On the negative side, it wasn’t as neatly commented or structured as GPT-4.5’s code. There could be big if/else chains or separate functions for each piece, which might be somewhat messy. But it’s still easier than coding from the ground up. You’d just need to carefully enhance the existing framework, while debugging any conflicts. All in all, DeepSeek brought us close to a complete solution, with a working UI and some game logic, but it fell short of finishing the job. This matches the general understanding of DeepSeek as a strong yet slightly lower-tier model—its R1 edition was praised for good reasoning at a cheaper cost, but it didn’t match the top contender’s thoroughness.
Grok 3
Grok 3’s output was the least successful in this comparison. We used same standard prompt + 2 additional hint prompts.

Grok 3’s result was the least successful here, showing several major weaknesses. For functionality, Grok 3 didn’t provide a standalone chess program. Instead of coding the rules itself, it relied on an outside library to handle the bulk of the logic. The HTML produced contained < script > tags that tried to load known chess engines or UI frameworks from somewhere else (like a CDN). This goes against the requirement of a single-file solution that contains all code, suggesting that Grok 3 either couldn’t or decided not to code the chess logic itself. Consequently, if you open the file offline or if the links fail, the board might not show up or the moves don’t work. Even online, the real logic is in the external code, so Grok 3’s file alone is basically just a wrapper with no full chess functionality.
As for design & UI, Grok 3 did minimal work. It mostly depended on whatever style the external script provided. If the linked library had its own default appearance, that’s what got shown. Grok 3 didn’t add much custom styling or Apple-like touches—no advanced color scheme or typography. If the external library didn’t load, you’d just see a blank page or an empty container. So the UI was either very basic or nonexistent. There was no sign of custom design or extra features. Essentially, Grok 3 handed over both the logic and the design to external sources.
Performance & efficiency are hard to judge for Grok 3 because performance depends on the outside resource. If it was an optimized library, the moves might be smooth online. If it didn’t load, the app fails. Also, external calls add loading time. And since we needed a one-file, portable solution, Grok 3’s approach is pretty much the opposite—relying on external scripts that might or might not be available. So from a portability standpoint, this is inefficient.
Concerning ease of modification, Grok 3’s code rates very low. It wrote very little itself—maybe some basic HTML skeleton and a few lines of JavaScript to initialize or configure the external library. For a developer wanting a self-contained chess app, it’s useless. You’d have to either embed the entire external library into the file yourself or rewrite the missing logic. The code had almost no helpful structure or comments from Grok 3. Essentially, you’d be starting over to fulfill the original single-file requirement. This response indicates Grok 3 might not have really “understood” the requirement to implement everything in one file, or it just couldn’t do it. Notably, Grok 3 is presented by xAI as an advanced model with high reasoning and coding ability scoring around 79.4% on a coding test, but the outcome here was poor. Possibly it misunderstood the prompt or was trained to rely on libraries. From a practical angle, Grok 3’s solution was a failure for this task: it didn’t meet the functional requirement or give code that could be simply adapted.
GPT-4o
GPT-4o approached the task from a design standpoint. We used same standard prompt + 2 additional hint prompts.

GPT-4o took a design-first angle, producing a beautiful chessboard interface but leaving out real chess rules. Looking at functionality, GPT-4o’s work must be called incomplete—it displayed the board with the correct piece layout but offered no move or rule checking. If you open GPT-4o’s HTML, you see a nicely rendered chessboard with the starting lineup, but trying to move a piece has no effect, since there’s no JavaScript for drag-and-drop or click-to-move. So it’s basically a static demo, not a functional game. No turn-based structure, no checks, no game flow—just a pretty board. GPT-4o seemingly focused on the “Apple-like” style aspect at the cost of the “fully functional chess” aspect. OpenAI says GPT-4o is a model with minor improvements, focusing on speed and cost-efficiency over GPT-4. It’s possible that it was coded to respond more quickly rather than handle heavy logic.
However, design & UI is where GPT-4o really did well. The interface was obviously in line with Apple-like design. GPT-4o used modern HTML and CSS with neat styling: a balanced color palette (maybe soft grays or silvers, with contrasting light and dark squares). It might include gentle drop shadows or gradient effects for a sleek, modern feel. Pieces were probably high-quality Unicode or SVG icons with a consistent, minimalistic style. The layout was neatly centered, maybe even responsive on different screen sizes. The minimal text or headings would have Apple-like typography. So visually, it was very polished, like a mockup that Apple might show. GPT-4o’s ability to produce an appealing front-end is clear—it’s great for quick prototypes of an interface.
On the performance side, GPT-4o’s app barely had any tasks, so it was very fast. It just rendered a static board with no real logic. The page loads immediately, with no complexity. There’s no risk of bugs or slowdowns from move calculations. This is a “static webpage,” so by definition it’s quick. However, we can’t say how it would perform if it had to handle actual chess rules. Possibly it would do fine with simpler logic, but that’s not shown here.
For ease of modification, GPT-4o’s code is both good and bad. The good: the HTML and CSS are likely well-arranged. The code is separated clearly, so changing the board’s colors or the piece icons would be simple. There’s basically no JavaScript to get confused by. The bad: there is no existing logic to build on, so you’d have to create all the chess rules and moves from scratch. The code structure might let you tag each piece or square, but you’d still have to write the entire interactive layer. That’s easier than removing or fixing flawed logic, but it’s still a big job. On the bright side, GPT-4o didn’t produce incorrect code that you must unravel. Instead, it’s a clean slate for the logic. Summing up, GPT-4o was great for a polished board design, but not good for a complete chess game. It might be enough if you just need a quick UI preview, but you’d need extensive extra coding for a playable version.
Claude 3.7
Claude 3.7 produced an outcome that sits somewhere between GPT-4o’s and DeepSeek’s. We used same standard prompt + 2 additional hint prompts.
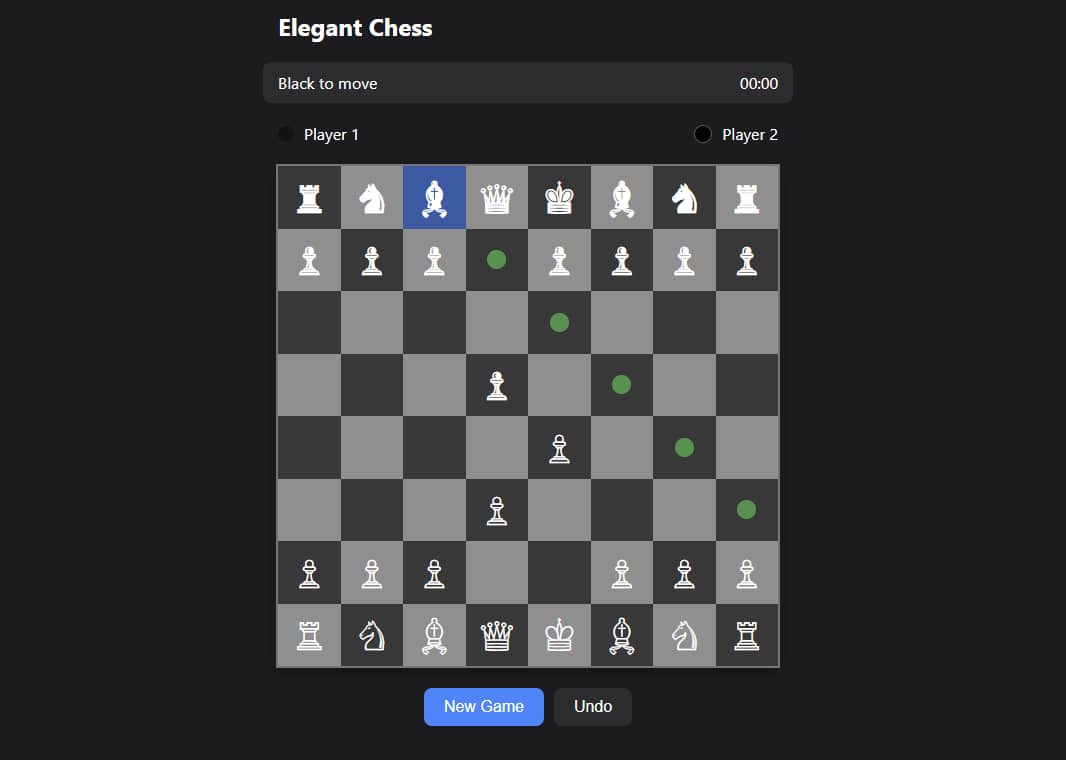
Claude 3.7 successfully overcame its initial limitations with some additional prompting, demonstrating its full potential by creating a fully functional chess game. Initially, Claude produced an aesthetically pleasing and interactive chessboard but lacked move validation and rule enforcement. However, after providing two additional prompts to clarify the requirement for comprehensive chess logic, Claude 3.7 delivered a complete chess application.
In terms of functionality, the revised application now fully supports legal chess moves, including special moves like castling, en passant, and pawn promotion. It also properly manages turn-based play, prevents illegal moves, and includes basic checks for checkmate and game-ending conditions, resulting in a legitimate and playable chess game suitable for two players.
On the design and UI front, Claude 3.7 continues to excel, providing one of the most visually appealing and engaging interfaces among the tested models. The chessboard uses a modern color scheme with visually attractive piece representations and smooth interactive animations, making the user experience both enjoyable and intuitive. It retains elegant touches such as hover effects and subtle piece animations, further enhancing usability.
Performance remains excellent, with smooth, lag-free interactions. Move validation and piece movements are responsive, thanks to efficient DOM manipulation and well-structured JavaScript. Claude’s application is entirely self-contained without external dependencies, ensuring quick loading times and consistent offline performance.
Regarding ease of modification, Claude 3.7’s updated codebase is cleanly organized and clearly structured. It separates the logic into distinct functions for piece movement, move validation, and game-state updates. Meaningful variable and function naming enhances readability, and the structured approach makes it straightforward for developers to extend or refine functionality further, such as adding advanced features like AI opponents or improved game analytics.
In summary, Claude 3.7, with just a bit of additional prompting, evolved from a visually impressive but rule-deficient chessboard into a robust and fully functional chess game, perfectly blending sophisticated UI design with comprehensive game logic. This showcases its strong capabilities in both front-end design and backend logic implementation, positioning it as a powerful tool for developers and designers alike.
Comparative Summary Table
| Model | Functionality (Chess Logic) | Design & UI (Apple-like?) | Performance | Ease of Modification (Code Quality) |
|---|---|---|---|---|
| GPT-4.5 | Complete: Full chess rules implemented (legal moves, check/checkmate, castling, etc.). Truly playable game. | Elegant & polished: Yes – Apple-like minimalism, responsive layout, interactive highlights. Feels professional. | Smooth: Efficient move validation, no lag or glitches. Self-contained with no external dependencies. | High: Clean, well-structured code with comments. Easy to understand and extend for future improvements. |
| DeepSeek | Partial: Basic movements work, but missing advanced rules (no castling, en passant; no check/checkmate detection). Playable only in part. | Functional: Decent UI with a proper board and pieces. Clean but not particularly fancy; somewhat plain compared to Apple standard. | Responsive: Handles simple moves well with minimal delay. No heavy computations (since logic is incomplete). | Moderate: Code has a reasonable structure for moves and board state. However, missing logic must be added; moderate effort needed to complete and polish the code. |
| Grok 3 | Incomplete: Did not implement logic itself – attempted to use an external chess library, resulting in no standalone functionality. Not truly playable. | Basic/Outsourced: Minimal UI work done by the model. Relied on external library’s default interface. Lacks custom styling; not in line with Apple-like elegance. | Uncertain: When online, performance depends on external library (generally okay); offline, the app fails entirely. Not self-contained, which is inefficient for portability. | Low: Little custom code present. Requires significant redevelopment (embedding library or writing logic from scratch). Hardly any structure to reuse – essentially starting over to meet requirements. |
| GPT-4o | None (Static): No game logic provided. Board is static with pieces fixed in starting positions. Not playable without adding code. Even after two additional hint prompts, no chess logic was implemented. | Highly Polished: Yes – visually impressive and clean. Apple-inspired design with careful styling. Looks great as a static mockup. | Excellent: Very fast load and render (only static content). No interactive lag since no heavy logic is running. | Low/Moderate: Front-end code is well-organized for the UI, so design tweaks are easy. However, adding full chess logic from scratch is required to make it functional. The provided code doesn’t guide game implementation. |
| Claude 3.7 | Limited: Initially produced an empty UI with no logic. After two additional hint prompts, generated a working UI allowing piece movement but no rule enforcement (no legality checks, no turn order, no endgame detection). Pieces can be moved arbitrarily. | Aesthetic & interactive: Yes – attractive, modern interface with some interactive elements (dragging pieces, etc.). Strong UX focus, though without rule feedback. | Great: Smooth interactions and animations. No complex calculations, so performance is fine. Everything runs client-side with no delays. | Moderate: Well-crafted UI code that is easy to adjust. Structure is in place to add logic, but all rule enforcement must be written. Understandable foundation, but needs significant expansion to become a full game. |
Conclusion & Recommendations
Creating a fully functional chess web application in one go is a demanding test for any AI model. Our comparison revealed a spectrum of outcomes: GPT-4.5 stands out as the only model that delivered a truly complete and playable chess game, combining robust functionality with an elegant UI. This makes GPT-4.5 the top recommendation if you need an AI to generate complex, working web applications. Its strength in reasoning and coding shines here – it not only knew the chess rules but also handled the intricacies of a slick user interface. GPT-4.5’s output would require minimal tweaking before deployment, demonstrating the incredible potential of cutting-edge models to handle end-to-end development tasks. AI model developers can take note of this success as a benchmark for what’s possible when model reasoning and adherence to instructions align perfectly.
DeepSeek, while not at GPT-4.5’s level, proved to be a strong contender. It got a lot right – the basic structure of the game and UI – but didn’t quite reach the finish line in terms of complete rules. For a free model (or a lower-cost alternative), DeepSeek’s performance is commendable. For use cases where cost is a concern or for getting a quick prototype, DeepSeek could be a viable choice, provided one is ready to do a bit of manual coding to patch up the missing logic. It illustrates how far newer competitors have come, nearly matching the performance of top-tier models in complex tasks. Prompt engineers working with DeepSeek might succeed in coaxing more complete logic by explicitly instructing it on each rule, or by breaking the task down (e.g., first ask it to write move-validation functions, then the rest of the UI).
Grok 3 was the outlier in a negative sense. It demonstrates that not all high-profile models are equal when it comes to strict coding tasks. Grok 3 has strong general capabilities and presumably strong coding potential given xAI’s claims and benchmarks, but in this instance it failed to follow the requirement of a self-contained solution. This could be due to its training (perhaps it “learned” that using libraries is acceptable or had insufficient knowledge of implementing chess logic). For projects where you must rely on Grok 3, the lesson is to write extremely clear prompts forbidding external resources and maybe iteratively build the solution (first ask it to outline, then to fill in code for each part). At its current state, we would not recommend Grok 3 for one-shot complex web app generation. It might serve in scenarios where using external APIs or libraries is acceptable, or for simpler coding tasks, but in our test it did not deliver.
GPT-4o represents a middle ground where the output was partially successful: it excelled significantly in UI/UX design but completely lacked implementation of game logic, even after additional prompting. GPT-4o could be particularly useful in design-centric or UI prototyping scenarios. For instance, if a UI/UX designer needs a visually appealing mockup of an application interface (such as a chess game) to present to stakeholders, GPT-4o’s strength in generating a polished, static front-end makes it very valuable. The resulting prototype would then require developer intervention to incorporate functionality and logic.
In contrast, Claude 3.7 initially produced an attractive and interactive interface without comprehensive chess logic but demonstrated its full capabilities after receiving two additional clarifying prompts. It successfully generated a fully functional chess game complete with legal moves, special moves (castling, en passant, pawn promotion), turn-based play, and check/checkmate detection. Claude 3.7 is highly recommended for scenarios where both UI visual polish and functional interaction are crucial. Its interactive UI feels realistic, engaging users visually and functionally. With targeted, iterative prompting (first focusing separately on HTML/CSS, followed by JavaScript logic implementation), Claude 3.7 can achieve robust, full-scale application development. Given Claude's known coding strengths, the initial shortfall likely resulted from interpretation nuances or output constraints rather than capability limitations. With thoughtful prompting, Claude 3.7 effectively bridges front-end excellence with comprehensive backend logic.
From a broader perspective, this comparison offers insights into AI’s capabilities in web development as of early 2025. The fact that any model could produce a working chess game (a task involving complex rules and state) is remarkable. It showcases the rapid progress in large language models’ understanding of not just natural language, but structured problem domains like programming and game logic. For AI enthusiasts and professionals, a few key takeaways emerge:
Model Selection Matters: If you need end-to-end functionality, choose the most advanced model available (even if it’s more expensive or limited in access) because lower-tier models might leave critical gaps. GPT-4.5 outperformed others by a clear margin here. The competitive landscape is evolving (with models like DeepSeek and Claude improving fast), but there’s still a gap in one-shot performance on complex tasks.
Prompt Clarity is Key: Some failings could be mitigated with better prompts. For example, explicitly telling Grok 3 “Do not use external libraries; write all code in pure JavaScript” or reminding Claude “Ensure all chess rules are enforced” might have yielded better outcomes. As a prompt engineer, always specify the critical requirements (self-contained code, completeness of logic, etc.) to give the AI the best chance at success.
Hybrid Approaches: The varying strengths suggest an interesting strategy – using models in combination. One of the latest workflows being discussed in the developer community is using one model for planning/architecture and another for coding. In our context, one could imagine GPT-4.5 generating the core logic and Claude 3.7 refining the UI, merging the best of both. While our comparison treated models individually, in practice nothing stops you from sequentially using multiple AI tools, each for what they do best.
Verification and Testing: No matter how good the model, always test the generated application thoroughly. Even GPT-4.5’s complex output should be run through test games to ensure no subtle rule is missed (e.g., does it correctly handle stalemate or threefold repetition draw?). Lesser models’ outputs definitely require testing and debugging. AI can accelerate development, but it doesn’t eliminate the need for a developer’s validation – especially for something as rule-intensive as chess.
In conclusion, the best model for generating a chess web app in one shot is GPT-4.5, given its superior ability to handle both logic and design seamlessly. For those without access to it, DeepSeek’s or Claude's 3.7 output can serve as a strong foundation with some assembly required. If your focus is on a slick interface and you’re prepared to code the game rules yourself, GPT-4o provide beautiful starting points. Grok 3, in its current form, is not recommended for this particular task unless significant improvements are made or you use it in a carefully guided, stepwise fashion.
The capability of AI models in web development is already impressive and is improving rapidly. The chess game challenge is just one example; the lessons learned here apply broadly to any project where you consider enlisting an AI model as a co-developer. The endgame is clear: combining human creativity and oversight with AI’s generative muscle can checkmate the traditional limitations of software development.